
古いファイルを削除してファイルの数を一定にする
ログの整理で使った。
# 古いファイルを削除してファイルの数を一定にする
n=`ls -l | wc -l`
m=$((n-100)) # 100個残す
if [ $m -gt 0 ] ;
then ls -rt | head -n $m | xargs rm; # 古い方から消す
else true; # 何もしない
fiワンライナーでは無理かな?
全ての記事をそのまま表示している。
とても重くなってしまっているかもしれない。
ログの整理で使った。
# 古いファイルを削除してファイルの数を一定にする
n=`ls -l | wc -l`
m=$((n-100)) # 100個残す
if [ $m -gt 0 ] ;
then ls -rt | head -n $m | xargs rm; # 古い方から消す
else true; # 何もしない
fiワンライナーでは無理かな?
org-modeで書いてはてなに公開したものを貼る。
文章さえ書けばはてなに移すのは楽だろうと思ったが、画像をアップロードしたりリンクを張り替えたりするのは結構な手間だったので次からはやめよう。
(以下は元記事)
この記事はIS17er Advent Calendar 2017の13日目の記事です。
jbuilderはOCaml用のビルドツールで、OCamlbuildやOMake, OASISの親戚です。jbuilderを使うとOCamlを使って書いたプログラムのビルドが楽にできます。
MinCamlをjbuilderでビルドするのを試したところうまく設定できたので、この記事ではその方法を書きます。
フォークレポジトリはこれです。
MinCamlのソースコードをダウンロードし、 ./to_x86 というスクリプトを実行しておきます。
このコマンドがないとそもそもビルドができません。
opamから行えます。
opam install jbuilderOCamlMakefileを使うのに Makefile が必要なように、jbuilderを使うには jbuild が必要です。
MinCamlと同じディレクトリに jbuild というファイルを作り、以下を記述します。
このファイルの書き方はかなり特殊だと思うので、ドキュメントを参照してください(自分でもこれであってるのかイマイチ自信がありません…)。
(jbuild_version 1)
;lexer, parser はモジュール名
(ocamllex (lexer))
(ocamlyacc (parser))
(library ; 実行形式以外のモジュールを詰めたライブラリを作る
(; トップモジュールの名前はMinCaml
(name MinCaml)
; MinCamlモジュールに詰めるモジュールを書く
; 読み込むと入力を受け付け始めるMain, Anchor以外すべて
; ":standard"でこのフォルダにあるモジュールを表し、 "\"以降で除外するモジュールを選択している
(modules (:standard \ main anchor))
; 依存している外部ライブラリ
(libraries (str))
; cのスタブの名前(float.c)
(c_names (float))))
(executable ; 実行形式
(; 実行形式の名前
(name main)
; Mainモジュールのみをコンパイルする
(modules Main)
; 依存ライブラリ: 上で定義したMinCamlモジュール
(libraries (MinCaml))))各モジュール間の依存関係を書く必要はなく勝手に推論してくれます。もし依存関係にループがあった場合はどのようにループしているかを示してくれます。そのため新しいファイルを後から追加しても設定の変更は必要ありません。
なお後述する jbuilder utop という機能を利用するために、「 main.ml と anchor.ml 以外のファイルをコンパイルしてライブラリ MinCaml を作り、そのライブラリを使って main.ml をコンパイルする」という、多少遠回りな方法を取りました。
main.ml が (同じディレクトリにある\*.mlファイルで定義されるモジュールではなく) MinCaml モジュール内のモジュールを使うように、 冒頭に open MinCaml を追加します。
open MinCaml (* 追加 *)
(* 以下は同じ *)
let limit = ref 1000
...以上の設定でビルドができるようになります。次のコマンドでビルドします。
jbuilder build main.exeこれで main.ml をコンパイルしたファイル ./_build/default/main.exe が作られます。
jubuilder utop コマンドjubuilder utop コマンドを実行すると、そのフォルダの =jbuild=ファイルで定義されたライブラリのビルドが行われ、そのライブラリをロードしたutopが起動します。
上のように `jbuild` を記述した上で `jbuilder utop` を実行すると以下のようになります。
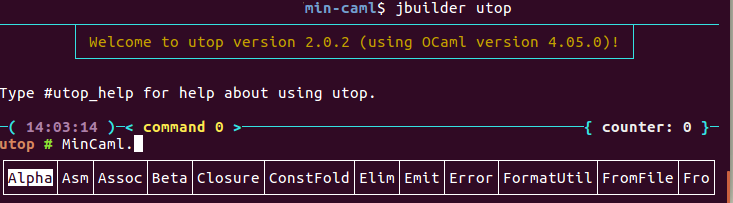
ライブラリのロードが行われるので、 モジュール名 (画像では`MinCaml`) を打つと補完が効きます。ソースコードの修正とデバッグを繰り返すときに便利です。
main.ml をコンパイルするのに MinCaml モジュールををわざわざ作った理由は、 Main モジュールがutopから読み込まれると標準入力を読み込み始めてしまうので除外する必要があったためです。
もともとのMinCamlはMakefileを使ってテストをするようになっているので、jbuilderと結合させます。
RESULT = min-caml
SRC = $(shell ls *.ml *.mli)
TESTS = $(shell ls test/*.ml | grep -v toomanyargs)
JBUILD_BUILD_PATH=./_build/default
default: $(RESULT)
# jbuilderを使ったビルド
$(RESULT): $(JBUILD_BUILD_PATH)/main.exe $(SRC)
cp $(JBUILD_BUILD_PATH)/main.exe $(RESULT)
$(JBUILD_BUILD_PATH)/main.exe: $(SRC)
jbuilder build main.exe
# モジュールをすべてロードしたutopを起動する
utop:
jbuilder utop
# 以下同じ
do_test: $(TESTS:%.ml=%.cmp)
...
これで `make`, `make do_test` が元のMinCamlと同じ意味で使えるようになり、 `make utop` でライブラリをロードしたutopが起動するようになります。
jbuilderの紹介はここまでです。
思いついたものを書きます。
ocamlのREPLで #install_printer hoge とするとそれ以降プリント関数として使うことができます。
具体的には
# type foo = A | B;;
# let print_foo fmt = function ;; 型fooのプリント関数
| A -> Format.fprintf fmt "this is value A"
| B -> Format.fprintf fmt "this is value B";;
val print_foo : Format.formatter -> foo -> unit = <fun>
# A;; ; print_installする前
- : foo = A
# B;;
- : foo = B
# #install_printer print_foo;;
# A;; ;; print_installした後
- : foo = this is value A
# B;;
- : foo = this is value B
# (A, B);; ;; 組み合わさっていてもOK
- : foo * foo = (this is value A, this is value B)とします。
なおプリント関数の型が t -> unit であっても動きますが、これは deprecated だそうです。(ソース)
REPLで Printexc.record_backtrace true とすると例外が出たときにどこから出たのか教えてくれます。
これがあればコンパイラをいじった結果 `Exception: Assert_failure` が全く予期しないところから生じても大丈夫です。
.ocamlinitocamlのREPLは立ち上がるときに同じディレクトリにある =.ocamlinit=を読むので、ここに毎回実行する処理を書いておくと楽です。
上のMinCamlでは
open MinCaml;;
(* エラーが出たときのバックトレースの有効化 *)
Printexc.record_backtrace true;;
(* プリント関数の有効化*)
#install_printer Syntax.print
#install_printer KNormal.print
#install_printer Closure.print
#install_printer Asm.printと書いています。
flambdaとはOCamlのネイティブコンパイラが持つ最適化機能の総称です。デフォルトの状態では(多分)有効化されないので、以下のコマンドで有効化されたコンパイラをビルドする必要があります。
opam switch 4.05.0+flambdaこれで -O3 オプションを付けてコンパイルすれば最適化が有効になります。
自分が書いたシミュレーターでは40%程度高速化しました。
CUDAを使って毎フレーム画像を更新したいが、いちいち画像をCPUに送り返している暇がないときに。
この前に書いたのはCUDAカーネルでビットマップを作成し、それをOpenGLを使って表示させる方法だった。このときはGPUで作成したデータを CudaMemcpy でホストへ送り返し、更にこれを glDrawPixels を使ってGPUへ送り返すという二度手間を行っていた。
CUDAとOpenGLを連携させる関数を使うと、データのやり取りをGPU内で完結させたまま同じことができる。データを送り返す必要がない分高速にできるので、アニメーションも可能になる。以下のようにすれば良い。
#define GL_GLEXT_PROTOTYPES
#include <GL/freeglut.h>
#include <GL/freeglut_ext.h>
#include <GL/gl.h>
#include <cuda_gl_interop.h>
#include <cuda_runtime.h>
#include <cmath>
#include <iostream>
// cudaのエラー検出用マクロ
#define EXIT_IF_FAIL(call) \
do { \
(call); \
cudaError_t err = cudaGetLastError(); \
if (err != cudaSuccess) { \
std::cout << "error in file " << __FILE__ << " line at " << __LINE__ \
<< ": " << cudaGetErrorString(err) << std::endl; \
exit(1); \
} \
} while (0)
// 画面の解像度
#define WIDTH 1024
#define HEIGHT 1024
// pixel buffer object
GLuint pbo;
// フレームバッファの取得に使用
cudaGraphicsResource *dev_resource;
// 画面更新の間隔 (ms)
int interval = 16;
// カーネル関数: bitmapに適当に色を塗る
__global__ void kernel(uchar4 *bitmap, int tick) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
// 連続的になるように...
float theta = tick / 60.0f * 2.0f * M_PI;
float theta_x = x / 60.0f * 2.0f * M_PI;
float theta_y = y / 60.0f * 2.0f * M_PI;
float r = fabs(sin(theta + theta_x));
float g = fabs(cos(theta + theta_y));
float b = fabs(sin(theta + theta_x) * cos(theta + theta_y));
bitmap[offset].x = (unsigned char)(r * 255);
bitmap[offset].y = (unsigned char)(g * 255);
bitmap[offset].z = (unsigned char)(b * 255);
bitmap[offset].w = 255;
}
// 描画用コールバック
void draw() {
// ピクセルバッファオブジェクトがバインドされているので、サイズを指定するだけで良い
glDrawPixels(WIDTH, HEIGHT, GL_RGBA, GL_UNSIGNED_BYTE, 0);
glutSwapBuffers();
}
// 画面を更新するコールバック
void update(int key) {
static int tick = 0; // 今何フレーム目?
uchar4 *dev_bitmap;
size_t size;
// フレームバッファをマップしてアドレスを取得
EXIT_IF_FAIL(cudaGraphicsMapResources(1, &dev_resource, NULL));
EXIT_IF_FAIL(cudaGraphicsResourceGetMappedPointer(
(void **)&dev_bitmap, &size, dev_resource));
// カーネル関数を呼ぶ
dim3 threads(8, 8); // 64スレッド/1グリッド
dim3 grids(WIDTH / 8, HEIGHT / 8); // 各ピクセルに1スレッドが割り振られる
kernel<<<grids, threads>>>(dev_bitmap, tick);
// カーネル関数の終了を待つ
EXIT_IF_FAIL(cudaDeviceSynchronize());
// リソースの開放
EXIT_IF_FAIL(cudaGraphicsUnmapResources(1, &dev_resource, NULL));
// ウィンドウの再描画を要求
glutPostRedisplay();
// interval msec後にまた呼び出す
glutTimerFunc(interval, update, 0);
tick++;
}
int main(int argc, char *argv[]) {
// OpenGLの初期化
glutInit(&argc, argv);
glutInitDisplayMode(GLUT_DOUBLE | GLUT_RGBA);
glutInitWindowSize(WIDTH, HEIGHT);
glutCreateWindow("animation");
// コールバックを指定
glutDisplayFunc(draw);
glutTimerFunc(interval, update, 0);
// バッファを作成
glGenBuffers(1, &pbo);
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, pbo);
glBufferData(GL_PIXEL_UNPACK_BUFFER,
sizeof(char4) * WIDTH * HEIGHT,
NULL,
GL_DYNAMIC_DRAW);
// OpenGLのバッファをCudaと共有する設定
EXIT_IF_FAIL(cudaGraphicsGLRegisterBuffer(
&dev_resource, pbo, cudaGraphicsMapFlagsNone));
glutMainLoop();
// リソースの開放(glutMainLoop()は返らないので、実際は呼ばれない)
glBindBuffer(GL_PIXEL_UNPACK_BUFFER, 0);
glDeleteBuffers(1, &pbo);
EXIT_IF_FAIL(cudaGLUnregisterBufferObject(pbo));
EXIT_IF_FAIL(cudaGraphicsUnregisterResource(dev_resource));
}
nvcc anim.cu -run -lGL -lglut で実行すると以下のようなアニメーションが表示される。
Cuda入門に出てきた関数をクラスにまとめたので、コピペ用に。
#ifndef CUDATIMER_H
#define CUDATIMER_H
#include <iostream>
#include <stdlib.h>
#include "cuda_runtime.h"
// cudaのエラー検出用マクロ
#define EXIT_IF_FAIL(call) \
do { \
(call); \
cudaError_t err = cudaGetLastError(); \
if (err != cudaSuccess) { \
std::cout << "error in file " << __FILE__ << " line at " << __LINE__ \
<< ": " << cudaGetErrorString(err) << std::endl; \
exit(1); \
} \
} while (0)
class CudaTimer {
private:
cudaEvent_t start, end;
public:
CudaTimer() {
EXIT_IF_FAIL(cudaEventCreate(&start));
EXIT_IF_FAIL(cudaEventCreate(&end));
}
~CudaTimer() {
EXIT_IF_FAIL(cudaEventDestroy(start));
EXIT_IF_FAIL(cudaEventDestroy(end));
}
// 計測開始
void begin() {
EXIT_IF_FAIL(cudaEventRecord(start));
}
// 計測終了
void stop() {
EXIT_IF_FAIL(cudaEventRecord(end));
}
// 測定結果を出力
void report() {
// イベントendが終わるまで待つ
EXIT_IF_FAIL(cudaEventSynchronize(end));
float elapsed;
EXIT_IF_FAIL(cudaEventElapsedTime(&elapsed, start, end));
printf("elapsed: %f ms\n", elapsed);
}
void stop_and_report() {
stop();
report();
}
};
#endif /* CUDATIMER_H */
上のプログラムを cudaTimer.h と保存すると、以下のように使える。
#include <cuda_runtime.h>
#include <stdio.h>
#include <unistd.h>
#include "cudaTimer.h"
// 何もしない
__global__ void empty() {}
int main() {
CudaTimer timer;
timer.begin();
// 何もしない関数を呼ぶとどれくらい時間がかかるのだろう?
empty<<<1024, 1024>>>();
timer.stop_and_report();
return 0;
}
上のプログラムを main.cu という名前で保存して以下のように実行すれば実行の時間を計測できる。
$ nvcc -run main.cu
elapsed: 0.017344 msc++のことをよく知らないのでクラスの作り方に自信がないが、今のところ特に問題なく使えている。
cudaでビットマップを作って、それをOpenGLを使ってウィンドウ上に表示したい。
プログラムでビットマップを作っても、それを表示させるのがめんどくさいことがある。これまでpythonでビットマップを作ったときには matplotlib.pyplot.imshow() を使ってきたが、c++とcudaを使ったときにはどうすればよくわからなかった。ppm画像に書き出してもいいが、いちいち画像エディタを開くのはめんどくさい。
openGLにはビットマップを描画するglDrawPixels()関数がある。これを使えば、cudaでビットマップを作成 -> OpenGLで描画、という流れが同じプログラム内で行える。
次のプログラムは簡単なビットマップを作ってそれをOpenGLで表示する。
#include <GL/gl.h>
#include <GL/glut.h>
#include <cuda_runtime.h>
#include <stdio.h>
#define WIDTH 512
#define HEIGHT 512
#define IMAGE_SIZE_IN_BYTE (4 * WIDTH * HEIGHT)
// エラー用マクロ
#define EXIT_IF_FAIL(call) \
do { \
cudaError_t retval = call; \
if (retval != cudaSuccess) { \
printf("error in file %s line at %d: %s\n", __FILE__, __LINE__, \
cudaGetErrorString(retval)); \
exit(1); \
} \
} while (0)
// グローバルのデータ(へのポインタ)をまとめたもの
struct DataBlock {
unsigned char *bitmap;
unsigned char *dev_bitmap;
static DataBlock *get_data() {
static DataBlock g_data;
return &g_data;
}
};
// カーネル関数: bitmapに適当に色を塗る
__global__ void kernel(unsigned char *bitmap) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
bitmap[offset * 4 + 0] = (x / (WIDTH / 255));
bitmap[offset * 4 + 1] = (y / (HEIGHT / 255));
bitmap[offset * 4 + 2] = ((x + y) / (WIDTH + HEIGHT) / 255);
bitmap[offset * 4 + 3] = 255;
}
// 描画用コールバック
static void draw() {
DataBlock *data = DataBlock::get_data();
glClearColor(0.0, 0.0, 0.0, 1.0);
glClear(GL_COLOR_BUFFER_BIT);
glDrawPixels(WIDTH, HEIGHT, GL_RGBA, GL_UNSIGNED_BYTE, data->bitmap);
glFlush();
}
int main(int argc, char *argv[]) {
DataBlock *data = DataBlock::get_data();
// ビットマップをデバイス/ホストに確保
data->bitmap = new unsigned char[IMAGE_SIZE_IN_BYTE];
EXIT_IF_FAIL(cudaMalloc(&data->dev_bitmap, IMAGE_SIZE_IN_BYTE));
dim3 threads(16, 16); // 16x16 スレッド per グリッド
dim3 grids(WIDTH / 16, HEIGHT / 16); // グリッドの数はthreadsとDIMから求まる
// カーネル呼び出し
kernel<<<grids, threads>>>(data->dev_bitmap);
// 出来上がったビットマップをホストへコピー
EXIT_IF_FAIL(cudaMemcpy(data->bitmap, data->dev_bitmap, IMAGE_SIZE_IN_BYTE,
cudaMemcpyDeviceToHost));
// メモリの開放
EXIT_IF_FAIL(cudaFree(data->dev_bitmap));
// 画像の描画
glutInit(&argc, argv);
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA);
glutInitWindowSize(WIDTH, HEIGHT);
glutCreateWindow("bitmap");
glutDisplayFunc(draw);
glutMainLoop();
// メモリの開放
free(data->bitmap);
return 0;
}
nvcc --run main.cu -lGL -lglut とすれば以下のウィンドウが出力される。
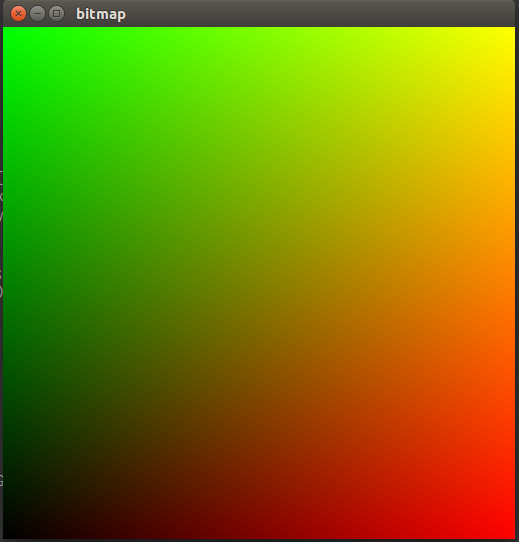
らくちん。